
2026 年 4 月 24 日,OpenAI 正式发布 GPT-5.5
GPT-5.5 能够更快地理解用户意图,并自主完成更多工作。它擅长编写和调试代码、在线研究、数据分析、创建文档和电子表格、操作软件,以及在不同工具间切换直到任务完成。与其精心地管理每一个步骤,不如给 GPT-5.5 一个复杂的多部分任务,让它自己规划、使用工具、检查工作、在模糊中导航,并持续推进。
核心突破:GPT-5.5 在保持与 GPT-5.4 相同延迟的同时,实现了更高水平的智能,并且消耗的 Token 数量显著减少。
核心能力
Agentic Coding(智能体编程)
GPT-5.5 是 OpenAI 最强大的智能体编程模型。
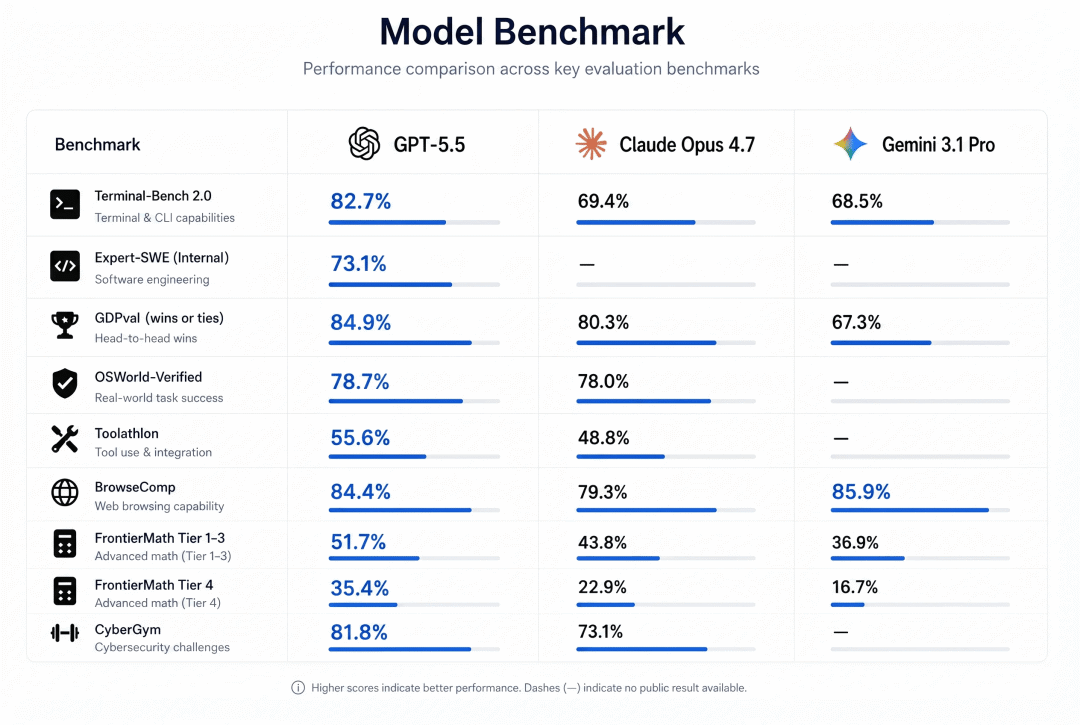
在 Terminal-Bench 2.0(测试复杂命令行工作流,包括规划、迭代和工具协调)上,达到 82.7% 的准确率,刷新 SOTA。
在 SWE-Bench Pro(评估真实 GitHub 问题解决能力)上,达到 58.6%,在单次通过中解决的任务比以前的模型更多。
在 Expert-SWE(内部前沿评估,针对人类预估完成时间中位数为 20 小时的长周期编码任务)上,同样超越 GPT-5.4。
关键发现:在这三项评估中,GPT-5.5 在使用更少 Token 的同时提升了 GPT-5.4 的分数。
Knowledge Work(知识工作)
GPT-5.5 在日常计算机工作方面同样强大。由于模型更好地理解意图,它能够更自然地完成知识工作的完整循环:查找信息、理解重要内容、使用工具、检查输出,并将原始材料转化为有用的内容。
在 Codex 中,GPT-5.5 在生成文档、电子表格和幻灯片方面优于 GPT-5.4。早期测试人员表示,在运营研究、电子表格建模以及将混乱的业务输入转化为计划等工作上,它超越了过去的模型。
Scientific Research(科学研究)
GPT-5.5 在科学和技术研究工作流方面也展现出进步。研究者需要探索想法、收集证据、测试假设、解释结果并决定下一步尝试。GPT-5.5 在跨越这个循环时比其他模型更好。
特别值得注意的是,GPT-5.5 在 GeneBench(专注于遗传学和定量生物学多阶段科学数据分析的新评估)上对 GPT-5.4 展现出明显提升。
基准测试
Coding(编程)
| 64.3% | ||||
| 82.7% | ||||
| 73.1% |
基准说明:
SWE-Bench Pro
评估模型解决真实 GitHub Issue 的能力,需要理解代码库、编写补丁、运行测试 Terminal-Bench 2.0
测试复杂命令行工作流,包括规划、迭代、工具协调,模拟真实开发环境 Expert-SWE
针对人类预估完成时间中位数为 20 小时的长周期编码任务
注:Anthropic 已在 SWE-Bench Pro 上注明存在记忆污染(memorization)证据,Claude Opus 4.7 的高分可能不完全代表真实能力。
Professional(专业领域)
| 84.9% | ||||
| 64.4% | ||||
| 54.1% |
基准说明:
GDPval
测试Agent在44个职业中完成知识工作的能力,包括信息整合、文档生成、决策支持 FinanceAgent v1.1
评估金融领域 Agent 的任务执行能力,包括财务建模、数据分析 OfficeQA Pro
测试办公软件(文档、表格、邮件等)的任务完成能力
Computer Use & Vision(计算机使用与视觉)
| 78.7% | |||
| 81.2% | |||
| 83.2% |
基准说明:
OSWorld-Verified
测试模型在真实操作系统环境中操控电脑的能力(点击、输入、导航) MMMU Pro
大规模多模态理解测试,考察视觉问答和跨模态推理能力
Academic(学术)
| 25.0% | ||||
| 51.7% | ||||
| 35.4% | ||||
| 94.2% |
基准说明:
GeneBench
:专注于遗传学和定量生物学的多阶段科学数据分析,需要处理模糊或错误数据 FrontierMath Tier 1–4
:前沿数学问题,Tier 4 为最难级别,包括IMO水平的证明和问题 GPQA Diamond
:博士级学科问题测试,涵盖物理、化学、生物等 Humanity's Last Exam
:设计用于对抗 AI 的高难度考试,需要深度推理
Cybersecurity(网络安全)
| 88.1% | |||
| 81.8% |
基准说明:
Capture-the-Flags
解决网络安全夺旗挑战的能力,涉及漏洞发现和利用 CyberGym
评估网络攻防实战能力,包括系统加固、入侵检测
Long Context(长上下文)
| 74.0% | |||
| 45.4% |
基准说明:
MRCR v2
多针检索测试,在长文档中精确提取散布的多处相关信息 Graphwalks BFS
图遍历测试,评估在超长上下文中进行复杂搜索的能力
Abstract Reasoning(抽象推理)
| 95.0% | ||||
| 85.0% |
基准说明:
ARC-AGI
抽象推理能力测试,模拟人类视觉逻辑推理,被视为 AGI 进展的关键指标 ARC-AGI-2 为更难版本,需要更复杂的推理链
可用性与定价
ChatGPT
GPT-5.5 Thinking
:面向 Plus、Pro、Business 和 Enterprise 用户 GPT-5.5 Pro
:面向 Pro、Business 和 Enterprise 用户,专为更难的问题和更高准确性工作设计
Codex
GPT-5.5 面向 Plus、Pro、Business、Enterprise、Edu 和 Go 计划 上下文窗口:400K Fast 模式
:Token 生成速度快 1.5 倍,成本增加 2.5 倍
API 定价
| $5 | $30 | |
| $30 | $180 |
上下文窗口:1M
成本效率:虽然 GPT-5.5 价格高于 GPT-5.4,但它既更智能又更高效。在 Codex 中,GPT-5.5 为大多数用户以更少的 Token 提供更好的结果。
社区反应
来自 Reddit r/OpenAI :
好评如潮:真能解决问题
JameisWeTooScrong · 14 points
"它刚刚修复了一个我两周都没能解决、有 20 个其他 Agent 都尝试过但失败的 bug。简直一次搞定。GOATED!"
spanglyearth · 5 points
"深表认同,确实很 GOATED,用量限制也还不错。"
价格争议:效率提升是否值得
Astronomaut · 51 points
"GPT-5.5 的价格是 GPT-5.4 的两倍:输入 $5/1M,输出 $30/1M"
bnm777 · 4 points
"它并不是节省 50% 的 Token 效率。我猜它消耗的 Token 比 Opus 4.7 还多约 1.35-1.5 倍。"
bitdotben · 6 points
"看起来主要是效率改进。5.4 xhigh 实际上并不比 5.5 差多少,但你需要开启 xhigh 模式,意味着要燃烧大量 Token。5.5 medium 就能匹配 5.4 xhigh。所以对较低消费用户来说,我们得到了一个更聪明的模型——因为我们本来就没用过 xhigh。"
基准测试争议
phil_thrasher · 12 points
"这可能是一个很棒的模型,但他们巧妙地避开了 Opus 4.7 领先的基准测试。他们把 SWE-Bench Pro 从对比表中拿掉,但在页面后面才提到。5.5 在这个基准上得分 58.6%,而 Opus 4.7 是 64.3%。他们还有什么没说的?"
Neat-Measurement-638 · 32 points
"他们的脚注说那是因为 4.7 在 SWE-bench 上记忆了一些答案。这听起来像个可疑的说法,但我查了 Anthropic 的博客,他们确实是这么说的。"
Healthy-Nebula-3603 · 7 points
"Terminal-Bench 不是更重要吗?Opus 4.7 是 56%,GPT 5.5 是 82%。Opus 落后太多了。"
灰度发布:分批推送
djack171 · 37 points
"我在网页版和移动端都还没收到。我是 ChatGPT Pro 套餐。"
Wise_Bus6623 · 6 points
"这需要一些时间。不会一下子向所有人开放,但你明天应该就能收到了。"
TheFrenchSavage · 4 points
"收到了!"

吐槽:API 访问、模型频繁更新
Nevetsny · 9 points
"而且没有 API……yet……'即将到来'"
indicava · 2 points
"我不明白为什么我们从来没在第一天就获得新模型的 API 访问?"
littlemissrawrrr · 0 points
"我就不能把我喜欢的模型保留超过两个月吗?!这是否意味着他们要取消 5.4T 了?"
br_k_nt_eth · 2 points
"到这个时候,模型已经在编写它们的新版本了。这是迭代更新,因为即使预训练不同,你也有相似的基础。你可以从基准测试中看到这一点。"





网友评论